
Shacl4Bib
Custom metadata validation of library catalogues

Presented at Semantic Web in Libraries 2025 conference

Several presenters of this SWIB edition mentioned quality related activities, moreover Professor Panigabutra-Roberts explained what she learned from SWIB. I will talk about a particular piece of the semantic web toolbox that I found reusable in the non-semantic world of data, so it is also a ‘what have the semantic web ever done for us’ kind of presentation. It will not suggest anything that moves forward semantic web in libraries per se, but I report about a ‘back propagation’ effect.

The Shapes Constraint Language (SHACL) is a formal language for validating RDF graphs against a set of conditions. The problem SHACL tries to solve is that semantic web builds on the open world assumption, shortly: we do not have a schema that provides restrictive rules about statements in a given context. SHACL and its implementations provide a dictionary and machinery to create such rules, and validate statements against them. This is a simple example. The PersonShape defines rules of Person nodes. Each person should have one and only one (maxCount is set to 1) social security number (denoted as ‘ssn’), that should be a string (the datatype property), and match a regular expression: 3 numbers, dash, 2 numbers, dash, 4 numbers (the pattern property).
I should mention an alternative approach called ShEx or Shape Expressions. For those who are interested in application of ShEx on semantic library data I highly recommend the collected works of Gustavo Candela. Today however I will not talk about the direct application of these approaches.

Most of these properties are meaningful for other data types. What is really semantic web specific is how SHACL tells which data element (the nodes and properties in an RDF graph) we should take care of. We have however similar mechanisms that can select a data element in non semantic web data: we have XPath for XML, JSONPath for JSON, column names for tables, even core bibliographical metadata schemas and serialization format have such tools, MARCSpec for MARC and UNIMARC, and Pica Path for PICA. With orchestrating these existing tools it is possible to implement the non RDF specific subset of SHACL to a wider range of data.

I implemented this idea in the (already existing) Metadata Quality Assessment Framework. The idea is called Shacl4Bib. It keeps cardinality related constraints, such as minimal and maximal count, value ranges, constraints against strings, comparisons of data found in the records, and logical operations. While working with real data sets and metadata practitioners, it became evident that we should introduce additional constraints and properties, such as checking the content types of URLs, or dimensions of images, and giving descriptions, and identifiers to individual rules, hide or skip them and setting dependencies between them. Shacl4Bib not necessarily should concentrate on data problems. It is also ready to find ‘good practice’. The user can assign different scores for success and failure criteria, for example: if a given property have a string value, that is the minimal requirement, it is better if it is a link to a term in a known dictionary, and it is even better if the dictionary is a supported one by the current organisation that runs the analysis. (It might be familiar for those who know the tiers of Europeana’s Publishing Framework.)

These rules can be set in a ‘schema’ that describes all metadata elements we analyse – so it does not necessarily describe all elements available in the metadata schema. This schema can be expressed via a Java API, with YAML or JSON configuration files. This example sets that the file to analyse is a CSV file, and we are interested in a single property: there should be one and only one URL and it should start with ‘http’ or ‘https’.

This presentation is not intended to be a tutorial, so I will just give you some starters. With numeric value constraints we can require that a value should be greater or smaller than a given scalar. With combination we can set value ranges.

We can set constraints for the length of a string value…

… set a list of acceptable values …

… create a regular expression …

… and set the (minimal or maximal) number of words.

We can compare data element values, such as the title should be different than the description (which is a frequent problem in aggregated collections such as Europeana), or the first page number of a paper should be less than or equal to the last one.

It is possible to combine these rules with logical operators. For example there should be one and only one identifier, and it should contain at least one character.

As mentioned before real life scenarios required to extend the original rule set. Here are four of them: checking the content type – that issues an HTTP call; checking if a value is unique – that requires a preliminary indexing, that is also part of the tool; setting dependencies between constraints – for example check value of an optional element only it is available; and checking dimensions of an image.

Now I will talk about three use cases in which Shacl4Bib has been utilized. The first one is the German Digital Library (shortly DDB), an aggregator of almost one thousand cultural heritage organizations in Germany. The Shacl4Bib supported quality assessment process intends to support the validation of incoming records that the partner institutions submit to the database. DDB accepts several metadata schemas. In the current phase we work with Dublin Core and LIDO. The tool analyses each record then aggregates the results and displays them in a dashboard.
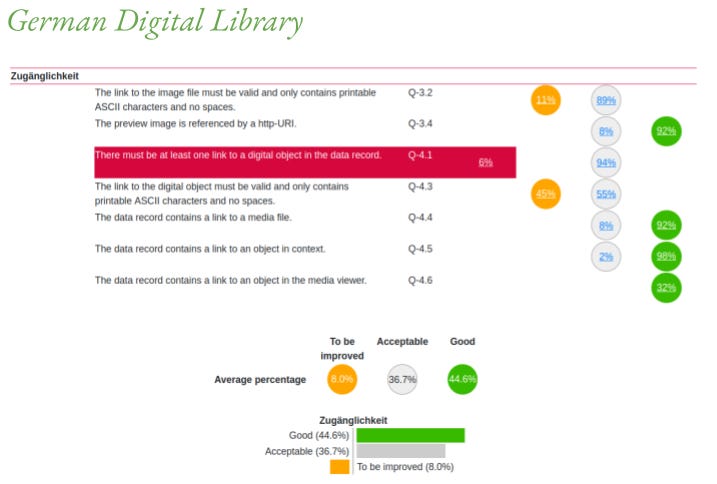
The dashboard provides both record level and aggregated overviews – here is a FAIR compliant one. There are four types of outcome: green means success, the records fit the criteria. Grey means “not applicable”, the record does not have the data element we have the criteria for. Orange means failure that we can live with, while red means failure that blocks the ingestion process.

In the rule definition only the ‘address’ or the data element is different. Both are expressed with XPath. Note that in Dublin Core we check two distinct data elements with one ruleset.
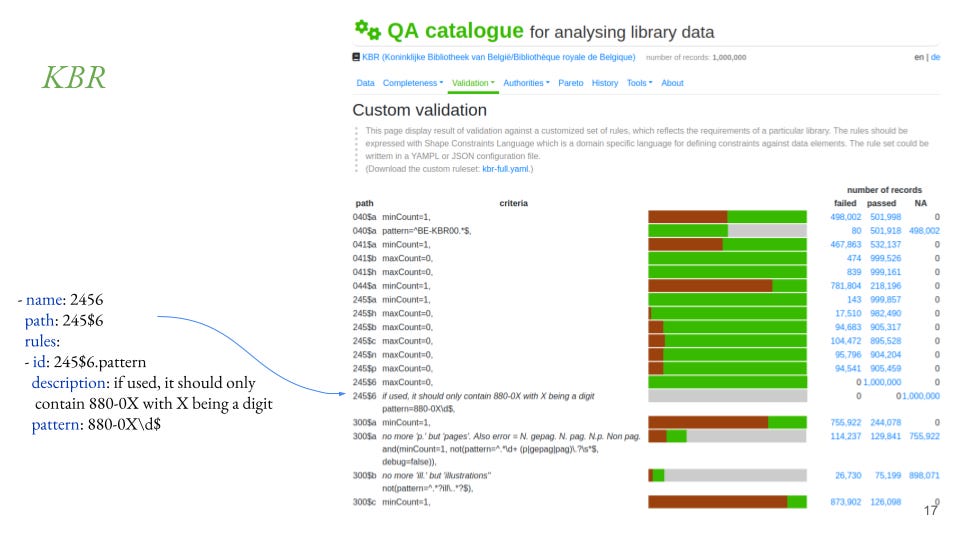
The second use case is the nightly quality assessment of the catalogue of KBR (previously known as the Royal Library of Belgium) based on QA Catalogue, a tool that extends Metadata Quality Assessment Framework. The metadata experts of KBR maintain the schema file that validates MARC21 records, and uses the MARCspec language to specify fields, subfields or indicators. The validation concentrates on the changes that come with the recent introduction of RDA in the cataloguing practice, and the special requirements of the library comes from its existing customs, and special situation. The dashboard similar to the previous one allows the user to check individual records having a particular problem (or a good example).
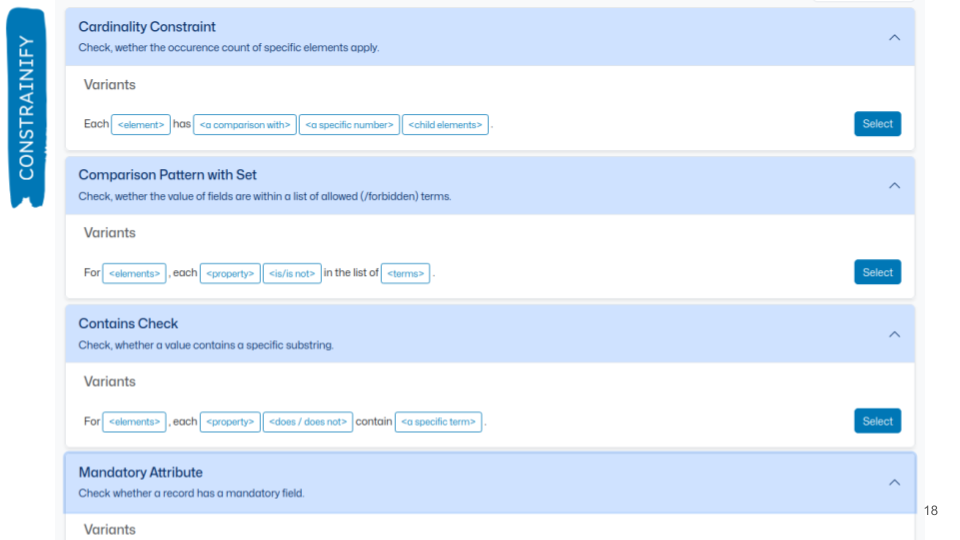
The Shacl4Bib approach eliminates the need of writing software code for validating the records, but still writing a configuration file is not a user friendly approach. Together with other quality assessment experts from the University of Marburg and Verbundzentrale des GBV (the maintainer of K10plus, the largest German union catalogue) within AQinDA project we work on a tool Constrainify that provides a ‘wizzard’ for metadata expert. Instead of starting from scratch the users can select human readable sentences typical in constraints definition, such as ‘For element X, each property Y does or does not contain a specific term.’ These sentences were distilled from documents describing metadata requirements created previously by partners such as DDB, KBR, Europeana and British Library.

The user then should fill the gaps with concrete metadata elements and scalars. The tool – now supports only TEI and LIDO – helps it by providing autocomplete and generated lists read from the metadata schema and its documentation.
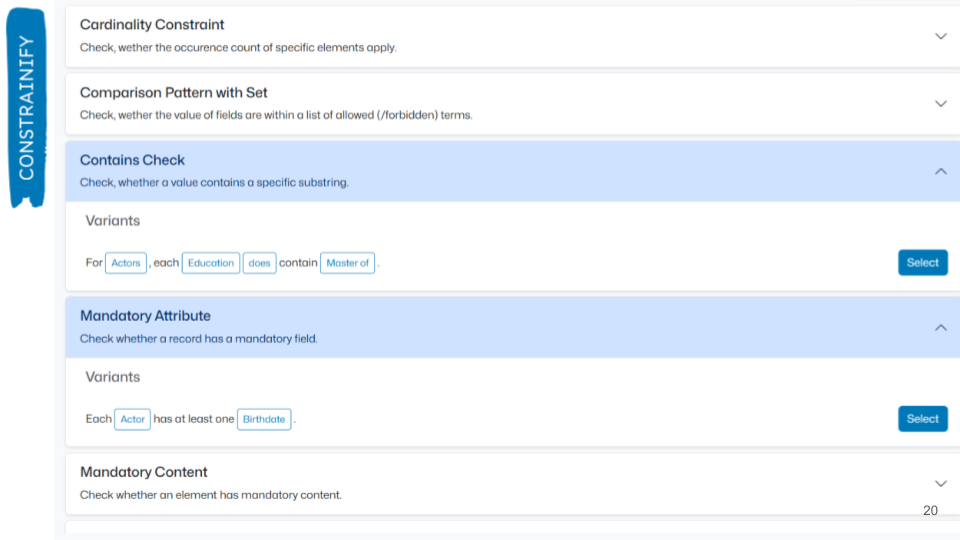
Once filled, the user has constraints like ‘Each Actor has at least one Birthdate’ or ‘For Actors each Education contains “Master of”’. The user then can execute the validation with the selected constraints, visit reports.
If you would like to know more about Shacl4Bib, please consult with these resources. I am happy to hear about your suggestions and critique. Happy coding and have a fruitful SWIB for the rest of the day!
References
Shacl4Bib paper: https://doi.org/10.48550/arXiv.2405.09177
Metadata Quality Assessment Framework: https://github.com/pkiraly/metadata-qa-api
Deutsche Digitale Bibliothek assessment (code): https://github.com/pkiraly/metadata-qa-ddb
QA catalogue: https://qa-data.kbr.be, https://github.com/pkiraly/qa-catalogue
Carsten Klee’s MARCSpec: https://marcspec.github.io
Jakob Voß’s PICA path: https://format.gbv.de/query/picapath
Constrainify: https://aqinda.gwdg.de, https://gitlab.gwdg.de/aqinda
Collected works of Gustavo Candela: https://orcid.org/0000-0001-6122-0777
slides: https://bit.ly/qa-swib25
Nice. Do you plan to use SHACL for inference rules as well?